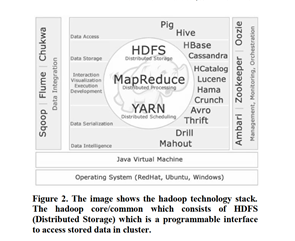
Hadoop est une solution logicielle distribuée. Il s’agit d’un système distribué évolutif et tolérant aux pannes pour le stockage et le traitement des données :
(i) HDFS (which is a storage)[ HDFS (qui est un entrepôt)]
(ii)Map Reduce (which is retrieval and processing): So HDFS is high bandwidth cluster storage and it of great use what is happening here is (Fig. 1)
[Réduire la carte (qui est la récupération et le traitement) : Donc HDFS est un stockage en cluster à large bande passante et ce qui se passe ici est d’une grande utilité (Fig. 1)]
Nous avons mis un fichier pent byte sur notre cluster Hadoop, HDFS va se
décomposer en blocs et ensuite le distribuer à tous les nœuds de notre cluster et en plus de cela nous avons un concept de tolérance aux pannes ce qui se fait ici est HDFS configure.
Facteur de réplication (qui est par défaut fixé à 3). C’est très utile et important parce que si nous perdons un nœud, il a une perception personnelle des données qu’il y avait sur le nœud et je vais répliquer les blocs qui étaient sur ce nœud. Il a un noeud de nom et un noeud de données généralement un noeud de nom par cluster mais essentiellement le noeud de nom est un serveur de métadonnées qu’il tient juste en mémoire l’emplacement de chaque bloc et de chaque noeud et même si
vous avez plusieurs configurations de rack il saura où le bloc existe et quels racks à l’intérieur du cluster dans votre réseau qui est le secret derrière HDFS et nous obtenons les données.
Map Reduce(Réduire la carte) : Maintenant, la façon dont nous obtenons les
données est par le biais de Map Reduce comme son nom l’indique, c’est un
processus en deux étapes. Il y a un Mapper et les programmeurs du Reducer vont écrire la fonction Mapper qui va sortir et dire au cluster quel point de données nous voulons récupérer. Le Réducteur prendra alors toutes les données et les agrégats.
Hadoop est un traitement par lots ici nous travaillons sur toutes les données du cluster, donc nous pouvons dire que Map Reduce travaille sur toutes les données de nos clusters. Il y a un mythe selon lequel il faut comprendre java pour sortir complètement des clusters, en fait les ingénieurs de facebook ont construit un sousprojet appelé HIVE qui est un interpréteur sql. Facebook veut que beaucoup de gens écrivent des jobs ad hoc contre leur cluster et ils ne forcent pas les gens à apprendre le java c’est pourquoi l’équipe de facebook a construit HIVE, maintenant n’importe qui qui est familier avec sql peut extraire des données du cluster.
Pig est un autre construit par yahoo, c’est un langage de flux de données de haut niveau pour extraire les données des clusters et maintenant Pig et ruche sont sous le travail Hadoop Map Reduce soumis au cluster. C’est la beauté du framework open source que les gens peuvent construire, ajouter et la communauté continue de croître dans Hadoop,